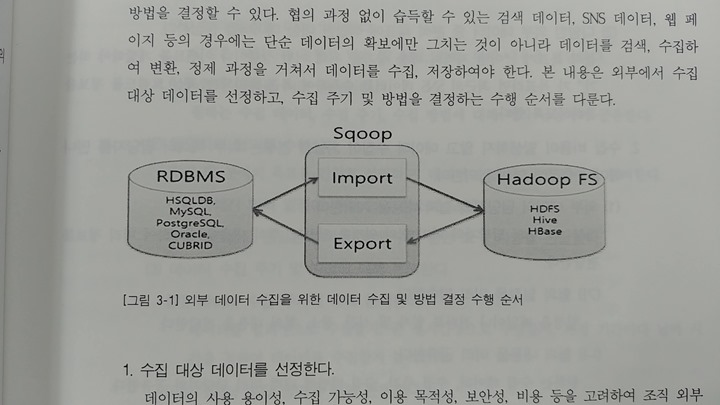
아파치 스쿱(apache scoop)은 관계형 데이터베이스와 같은 관계형 데이터스토어와 하둡(apache hadoop)간 대량의 데이터를 효과적으로 전송하기 위해 구현된 툴이다. 즉 MySQL, Oracle 환경의 데이터를 Hbase, Hive 또는 HDFS로 데이터를 import 할 수 있다.
sqoop의 명령어는 인터프리터에 의해 한 번에 하나씩 실행되며 모든 적재 과정을 자동화하고 병렬처리 방식으로 작업한다. 전체 DB 또는 테이블을 HDFS로 전송하는 bulk import를 지원하고, 시스템 사용률과 성능을 고려한 병렬 데이터 전송이 가능하며 자바 클래스 생성을 통한 프로그래밍 방식의 데이터 상호작용을 한다.
관계형 데이터베이스에서 익어온 테이블을 HDFS에서 파일 세트로 저장한다. 병렬처리 방식으로 적재하기 때문에 적재한 후에 HDFS에서 여러 개의 파일로 저장된다. 반대로 sqoop을 사용하여 HDFS에 저장된 파일 세트를 읽고 관계형 데이터베이스로 적재하는 것도 가능하다.
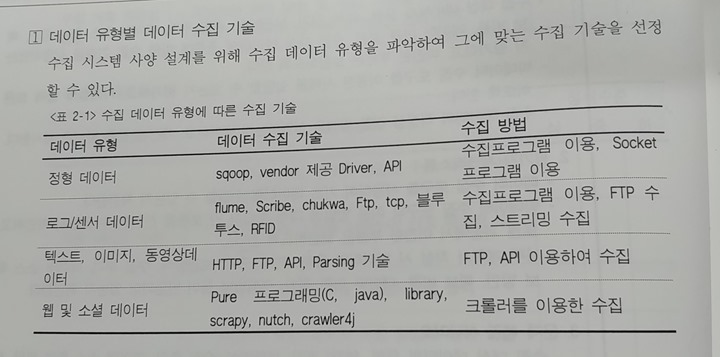
빅데이터 분석에 있어서 대표적인 데이터 유형인 로그/센서 데이터를 수집하는데 사용하는 기술들 중에 apache flume은 대용량의 로그 데이터를 효과적으로 수집하고, 집계하고, 이동시키는 안정적이고 신뢰성 있는 분산 서비스를 제공하는 솔루션이다. 스트리밍 데이터 흐름에 기반을 둔 간단하고 유연한 구조를 가진다.
이 `플룸`은 로그 데이터 수집에만 사용되지는 않는다. 네트워크 트래픽 데이터, 소셜 미디어 데이터, 이메일 메시지 데이터 등 대량의 이벤트 데이터 전송을 위해서도 사용하며 특징으로 장애시 로그 데이터의 유실없는 전송이 보장되어 신뢰성이 높은 편이고, 수평 확장으로 분산 수집이 가능한 구조와 최적화를 통한 성능 향상의 효율성이 있다.

텍스트, 이미지, 동영상, 웹과 소셜 데이터 등의 비정형, 또는 반정형 데이터 수집은 주로 FTP, API, library를 이용한 개발 및 crawler를 이용하여 수집한다. 웹사이트를 크롤링하고 구조화된 데이터를 수집하는 애플리케이션 프레임워크인 스크래피(scrapy)는 데이터마이닝, 정보처리, 이력기록 같은 다양한 애플리케이션에 유용하게 사용할 수 있다.
파이썬 기반의 프레임워크로 스크랩 과정이 단순하다. 특히 한 번에 여러 페이지를 불러오기 수월하고, 부가적인 요소들이 많다. 크롤링 후 바로 데이터 처리도 가능하면서 쉬운 수집과 로깅을 지원한다.
'ICT와 AI 정보' 카테고리의 다른 글
| 비주얼 스튜디오 코드에서 한글이 깨져 나올때 해결방법 (0) | 2020.07.07 |
|---|---|
| 함수형 언어 맵리듀스(MapReduce) (0) | 2020.06.29 |
| 파이썬(Python) 설치 및 패키지 인스톨러와 pip 매니저 (0) | 2020.06.27 |
| 아파치 톰캣(Apache Tomcat) 설치하기 (0) | 2020.06.23 |
| 흰색과 파스텔 색상의 무선키보드와 마우스 세트 (0) | 2020.06.16 |
| 가상머신 VMware 설치하기 (0) | 2020.06.12 |
| NotePad++ 다운받고 설치하기 (0) | 2020.06.09 |
| 빅데이터 관련 서적 (0) | 2020.06.08 |

 Rss Feed
Rss Feed